
A Generative Adversarial Network for AI-Aided Chair Design
Zhibo Liu, Feng Gao, Yizhou Wang
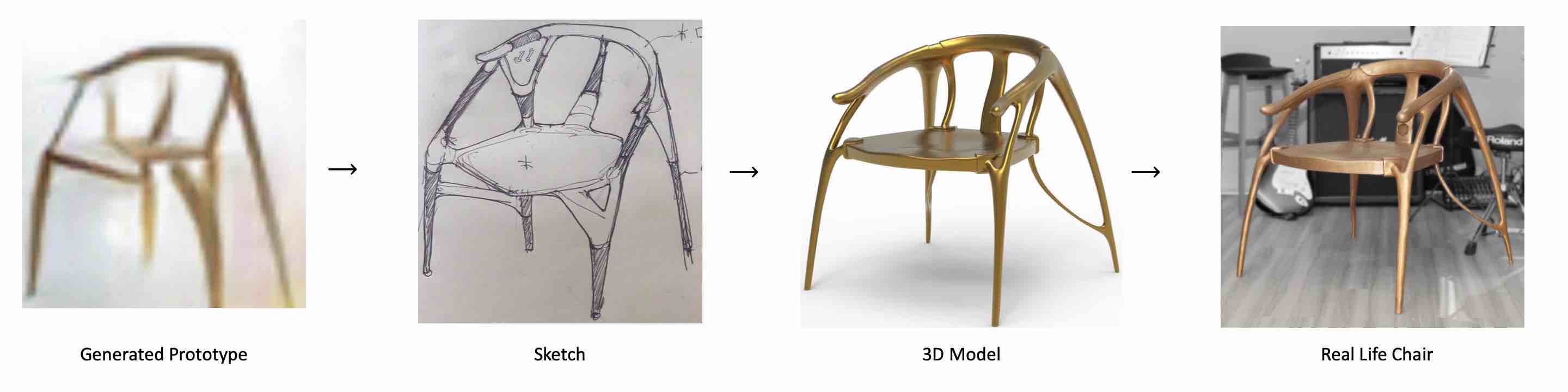
We present a method for improving human design of chairs. The goal of the method is generating enormous chair candidates in order to facilitate human designer by creating sketches and 3d models accordingly based on the generated chair design. It consists of image synthesis module, which learns the underlying distribution of training dataset, super-resolution module, which improve quality of generated image and human involvements. Finally, we manually pick one of the generated candidates to create a real life chair for illustration.
Dataset Around 38,000 chair images scraped from Pinterest for image synthesis module. We downscale the images by a factor of 4 for fine-tuning the image super-resolution network.
We generate 320,000 chair design candidate at \(256 \times 256\) resolution and spend few hours on selecting candidates as prototype. Finally, a real life chair is made based on the 2d sketch and 3d model of a prototype

Network Architecture We present a deep neural network for improving human design of chairs which consists of image synthesis module, super-resolution module.
For image synthesis we adopt DCGAN architecture whose generator consists of a series of 4 fractional-strided convolutions with batch normalization and rectified activation applied. And the discriminator has a mirrored network structure with strided convolutions and leaky rectified activation instead. For super-resolution we adopt the architecture of SRGAN with \(i=5, j=4\) for perceptual content loss \(\mathcal{L_{content(5,4)}^{sr}}\)
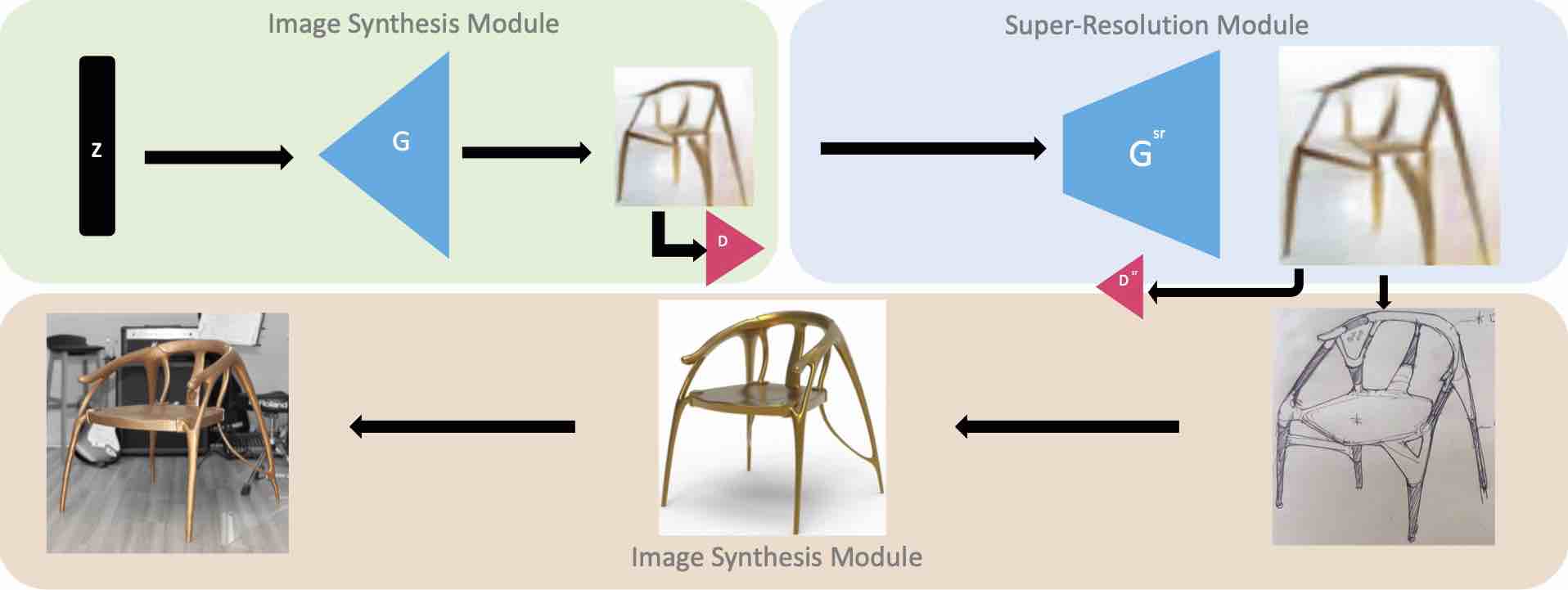
Image Synthesis Module
For generator \(G\) and discriminator \(D\), we express the objective as:
\[\mathcal{L}_{GAN}^{gen}(G,D) =\min_{G}\max_{D} E_{x\sim p_{chair}(x)}[\log D(x)] + E_{z\sim p_{Z}(z)}[\log (1-D(G(z)))]\]Where \(G\) tries to generate image \(G(z)\) that is indistinguishable from discriminator \(D\). At the same time, the discriminator \(D\) aims to distinguish between real chair samples \(x\) with generated images \(G(x)\).
Super-resolution Module
We apply adversarial loss and perceptual content loss to generate higher resolution images. Let \(y_{hr}\) and \(y_{lr}\) be images from high resolution domain and corresponding low resolution domain. \(G_{sr}\) and \(D_{sr}\) be the generator and discriminator of super-resolution module. The adversarial loss function is:
\[\mathcal{L}_{GAN}^{sr}(G_{sr},D_{sr}) =\min_{G_{sr}}\max_{D_{sr}} E_{y_{hr}\sim p_{train} (y_{hr})}[\log D_{sr}(y_{sr})] + E_{y_{lr}\sim p_{G_{sr}}(y_{lr})}[\log (1-D_{sr}(G_{sr}(y_{lr})))]\]The difference between a high resolution image \(y_{hr}\) and super-resolution image \(G_{sr}(y_{lr})\) is measured by perceptual content loss given a pretrained VGG19 network :
\[\mathcal{L_{content|i,j}^{sr}}(G_{sr}) =\frac{1}{W_{i,j}H_{i,j}}\sum_{k=1}^{W_{i,j}}\sum_{l=1}^{H_{i,j}}\big\{\phi_{i,j}(y_{hr})_{k,l} - \phi_{i,j}[G_{sr}(y_{lr})]_{k,l}\big\}^2\]Where \(\phi_{i,j}\) is the feature response of \(i^{th}\) layer and \(j^{th}\) filter. \(W_{ij}\) and \(H_{ji}\) indicate the dimensions of the respective feature maps of VGG19 network.
Training We used 2 GTX1080Ti GPUs to train image synthesis module for 200 epochs with mini-batch size of 128, learning rate of 0.0002 and Adam with \(\beta_1 = 0.9\) . In order to improve super-resolution performance on chair data, we fine-tuned SRGAN on downscaled chair dataset.

Result
We select one of the candidates as design prototype and create a real life chair based on it. To the best of our knowledge, this is the first physical chair created with the help of deep neural network, which bridges the gap between AI and design.
